
前編はこちら。 「改めて知りたい、人工知能とは何か?:新刊『人工知能のための哲学塾』第零夜(前編)」
「人工知能のための哲学塾 第零夜」(中編)目次
第3節 機械論的人工知能
・エージェントアーキテクチャ
・サブサンプションアーキテクチャ
第4節 意識モデル
・意識を実装する
・総合的な意識モデル
第3節 機械論的人工知能
この節では、デカルト的世界観(ここでは機械論的世界観という意味でこれを言いますが)でどこまで人工知能が作れるのかを見ていきたいと思います。知能を考えるときのキーワードは、機能、性質、ダイナミクスです。これらをプログラムによって作っていきます。
ここではあまり深入りしませんが、人工知能の大きな流れとしてシンボリズムとコネクショ二ズムという2つの流れがあります。いま流行っているディープラーニングのようなニューラルネットワーク上のアルゴリズムは、コネクショニズムと呼ばれます。これはニューロン(神経素子)をノードとする数学的なネットワークで知能を実現しようするところから、その名前が取られています。

一方、シンボリズムは記号によって知能を表現しようという方向です。記号というのは世界に結びつくことができる(シンボルグラウンディング)という考え方が元になっています。記号系と世界の間の対応がきちんと対応しているのか、という議論が、記号接地問題(シンボルグラウンディング問題)と言いますが、ここでは深入りしません。書籍の方のコラムとして解説します(『人工知能のための哲学塾』p52〜参照)。
コネクショニズムのほうは、明示的に知識を表現しにくくなります。ニューラルネットワークというのは、ノードをつないだ数値的なネットワークなので、ネットワークが入力に対して何かを認識する。認識したことは明確に言語化できない、できないからこそ、コネクショニズムはシンボリズムと明確な違いがあり、それが長所であり短所なのです。
シンボリズムでは、明示的に記号系で知識を表現しなければいけません。コネクショニズムはシンボリズムと仲が悪いというわけではありませんが、2つの独立した大きな潮流を人工知能の中で形成しています。コネクショニズムは、2000年頃は今よりはまだ小さかったのですが、最近はディープラーニングの流れを受けてかなり大きくなってきています。多層的なニューラルネットワークであるディープラーニングは、オートエンコーダーという特殊な学習法を行うことで、入力データの特徴量を各階層で自動抽出するのが特徴です。
ただ、大勢としてはシンボリズムが主流であり、インターネットが普及した段階で、世界に記号という記号、言語という言語が溢れて、とても大きな広がりを獲得しました。ですが、記号処理の限界が見えてきました。ディープラーニングの躍進をはじめとして、記号的でないものに対する処理の向上が起こりました。画像や映像に対しては、コネクショニズムの方が知的な処理を行うには強いわけで、コネクショニズムがやや力を取り戻しつつあります。ただ世の中の99%以上のソフトウェアは記号を処理していることを覚えておきましょう。またこの2つの流れが明確に融合する地点が新しい人工知能の沃野となることも覚えておきましょう。
エージェントアーキテクチャ
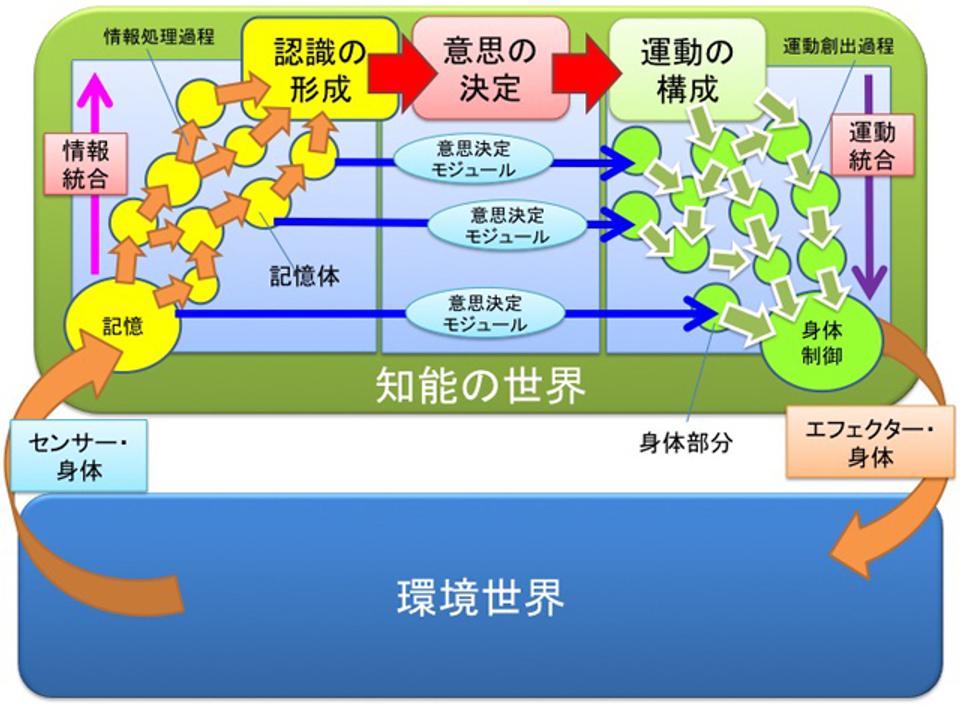
いま、知能をこういう図で表現します。まず、一番上の「認識」について考えてみましょう。世界の中に環境世界と知能の持つ身体があって、その2つの間には境界があります。
つまり身体と環境世界の境界には、皮膚があり、耳があり、目があり、鼻があり、舌があり、感覚があります。それを境界として、身体の中に知能があるわけです。環境と知能を分離してから、知能を考えようというのが、エージェントアーキテクチャの考え方です。またデカルト的な考え方でもあります。身体は知能と環境の界面にあり、世界と知能を機械仕掛けの中で理解しようとします。
キャラクターの人工知能を作るときは、こうしたエージェントアーキテクチャというものを描きます。まず、環境世界と知能世界を分離して、知覚(センサー)によって知識を獲得し、意思決定があって、運動の生成があって、身体を通して環境世界に運動を還元します。センサーによる入力と身体的な物理的な衝撃などもすべてふくめて知能(身体的知能をふくむ)に報告されます。こういった原理をプログラムによってゲームの中で動かします。
すると、世界と知能の間を情報がぐるぐる回ります。まるで水車のように、情報が流れることで知能が回る。これがインフォメーションフロー、情報の流れと呼ばれる、デジタル空間の中で知能を動かす力となるものです。世界と知能の間で情報が循環し、知能がぐるぐる水車みたいに回っていくというのが、ゲームキャラクターの人工知能全体のかたちのひとつです。これは、やはりデカルト的世界観の上に立脚した機械仕掛けの人工知能とも言えます。
サブサンプションアーキテクチャ
もうひとつ、遅延系という話があります。知能の最も根底の部分では、環境からのインプットが、すっとアウトプットにつながる。これが反射です。ただ知能が次第に高くなると、インプットがアウトプットにつながる反射の流れの上に、もう一層、「いったんインプットを解釈して新しい情報の経路を作ってアウトプットする」といった層をかぶせます。こういうふうにどんどん情報処理の階層が増え、反応が遅延していく。解釈して、階層化して処理する。
たとえば動物でいえば、第1層は反射的な行動。反射的な行動ばかりしているというのは、ちょっと言葉は悪いかもしれませんが、バッタのように、何か振動があれば次の草に向かって飛ぶような行動を取ることです。
少し知能をつけて、リスくらいになると、場合に応じた行動ができる。周囲の状況をいったん解釈して、逃げるべきか/動かないべきかを判断する。人間になると抽象的に思考して、未来の目標とか理念などにもとづいて行動し始める。
しかし階層化、抽象化には、反応速度の遅延という犠牲がつきまといます。たとえば、バッタの反応が一番すばやい。学者とか哲学者になると考え過ぎて反応が遅くなる。知能の層を重ねれば、より時間のかかる情報処理の流れが支配的になっていきます。
このような知能の構造を階層構造といいます。さらに、上の層が下の層をコントロールする権限を持つ階層構造を「サブサンプション構造」(subsumption architecture、日本語では包摂構造、包含構造)と言います。最近はお掃除ロボットに入っていますね。
サブサンプション構造は、MITのロドニー・ブルックスが1980年代後半に考案しました。あるときは下の層を上の層から抑制し、あるときはそのまま動かすことで、すばやく環境に適応する能力を持ちながら、同時にそれを上から見てコントロールしつつ自らもまた判断する知能の作り方のことを言います。
ゲームの人工知能もこうやって基本的な反射層を作っていきます。まず、反射的なものを作って、次にもっと考えるものを上の層に作る。反射層をラップする(囲う)ように、一層、さらに一層と積み上げながら作っていきます。そこでサブサンプションアーキテクチャには、包含構造という訳語が当てられているのです。
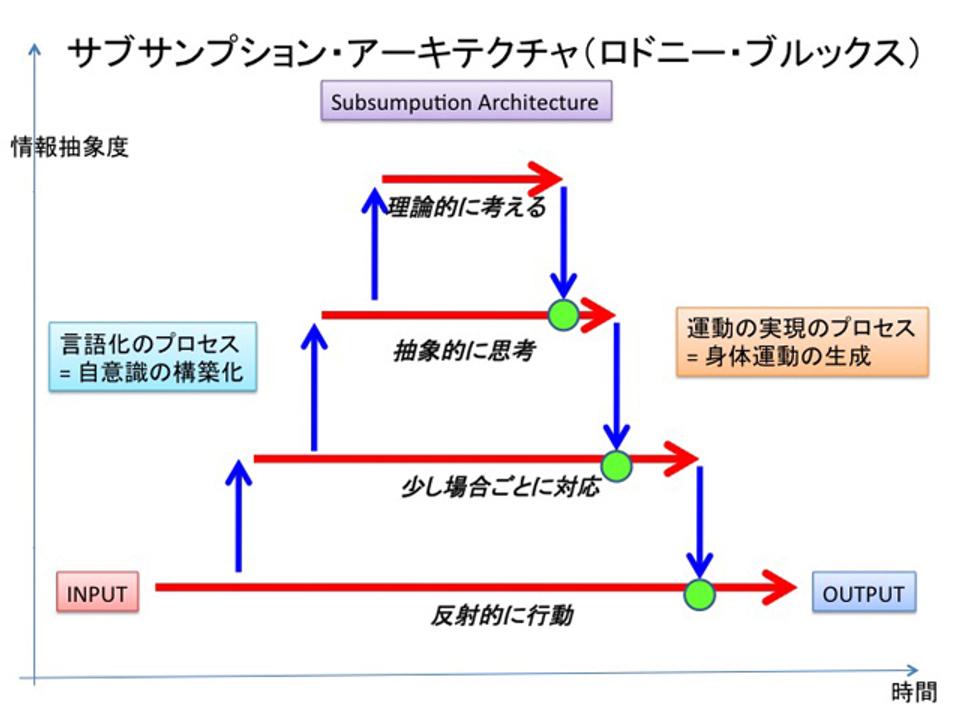
人工知能のもうひとつの作り方として、トップダウンに作っていくという方向があります。先ほど説明したシンボリズムから入ると、知能を抽象的な上から作ってしまうので全然(現実の)世界にたどり着かない。抽象的な思考はできるが環境に適応できない。もっと言えば、シンボルがうまく世界に結び付かない。つまり、シンボルがグラウンディング(接地)しない。では、世界との深い関連を持つ最下層から積み上げましょうというのがサブサンプション構造の目指す方法です。
知能を探究していくと、知能が主観的に知覚を通してとらえる世界と、知能が行動しようとするときに見える世界があることに気づきます。それが重なり合って世界が見えています。
このサブサンプションの図で言えば、情報が抽象化していく過程と、行動を展開していく先の世界が重なって見えていることになります。各層はそれぞれに世界をとらえていて、その各層がとらえている世界が多重に重なり合って認識世界が作られています。
我々自身もまたそうです。我々が意識的に世界をとらえている世界だけでなく、我々の内なる原始的な知能たちもまた世界をとらえており、それが無意識を構成し、世界をとらえています。意識的な世界、無意識的な世界をふくめて人間の認識が形成されます。ですから、緊張して意識的な知能だけで物事を解決しようとすると、急に性能がダウンします。落ち着いてリラックスして意識的な知能、自分の内なる無意識的な知能を総動員してこそ、フルな性能を獲得できるのです。
第4節 意識モデル
これは独立したトピックになるのですが、次に「意識モデル」について話したいと思います。意識というのが電気的に作れるのかという議論は昔からあります。電気回路、電子回路、そしてプログラムと、そこに意識が発生するかどうか、という問いです。ゲーム業界でもキャラクターに意識を持たせたいということから、いろいろな試みがされてきました。Machine Consciousness(MC、マシンの持つ意識)といいますが。
これまでゲーム分野ではあまり研究されてこなかったのですが、5年前くらいから盛り上がってくるようになりました。ゲームなので、実際に実装できるようなモデルを求めたいわけです。もちろん「意識とは何か?」という答えもまだわかっていない問題ですから、完成したモデルというよりは、その一端でもつかみたい、実現したい、というのが狙いです。
意識を実装する
意識には二種類の意識があるという説があります。P-ConsciousnessとA-Consciousnessです。という話があって、P-Consciousnessは主観的に体験されるもの、環境に対する意識、のことで、虹が綺麗だとか、リンゴは赤いとか、夕日はまぶしい、とか、そういった世界に対する意識です。
A-Consciousnessは自分の思考や意思決定に対する内面的な意識です。自意識と言っていいでしょう。このA-Consciousnessで知能を作ろうという試みがあります。こういうときは、たいてい3つの技術を組み合わせます。Blackboard Architecture(黒板モデル)、Global Workspace Theory(GWT)、Multiple Draft Model(MDM)です。
(1)黒板モデル (Blackboard Architecture)
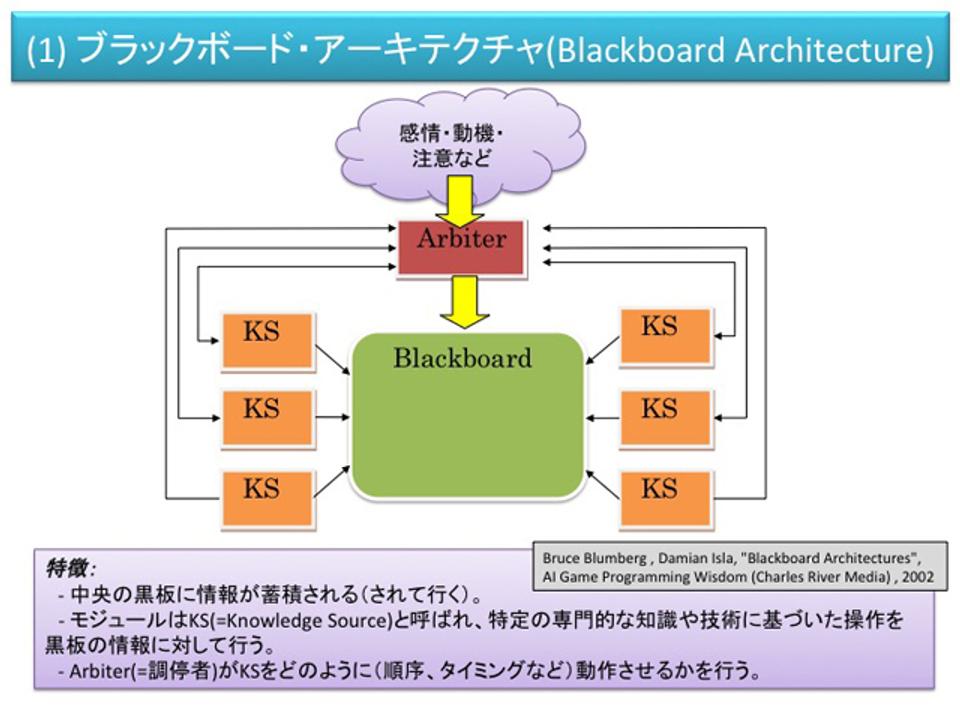
Bruce Blumberg , Damian Isla, "Blackboard Architectures", AI Game Programming Wisdom (Charles River Media) , 2002
黒板モデルというのはすごく簡単なモデルで、これは人工知能のひとつの型です。記憶体(Blackboard)と知識を書き込むナレッジソースがあって、ナレッジソースが調停者(Arbiter)の指令にしたがってBlackboardに書いたり消したりすることで、いろいろな知識をため込んだり、加工したりする。実は、現在のゲームキャラクターのアーキテクチャの基礎になっているのが、このBlackboard Architectureです。
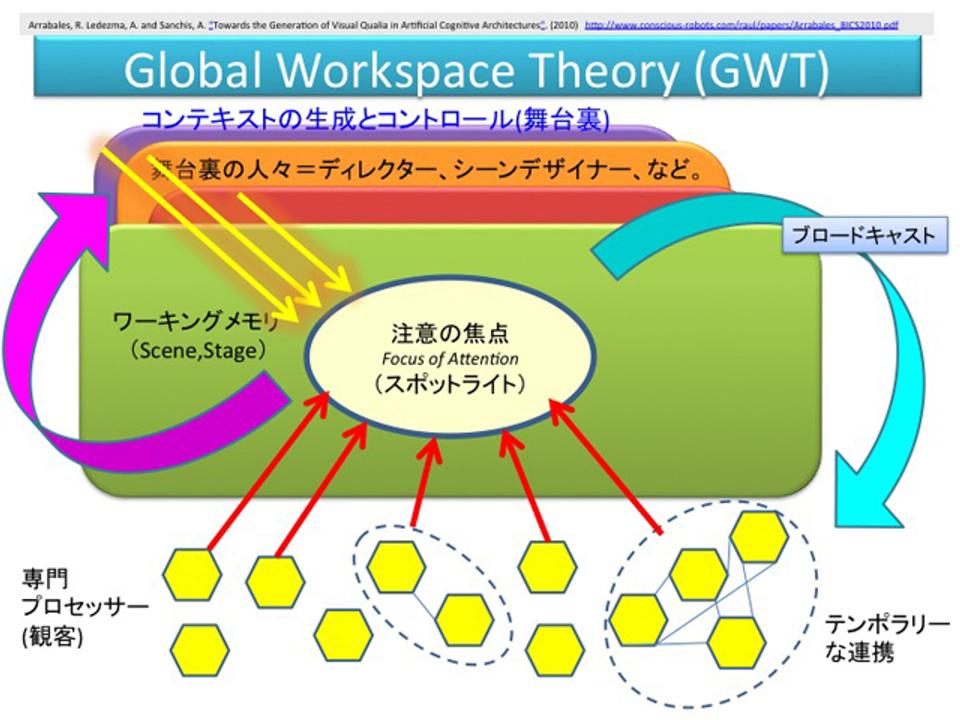
(2)Baar's Global Workspace Theory
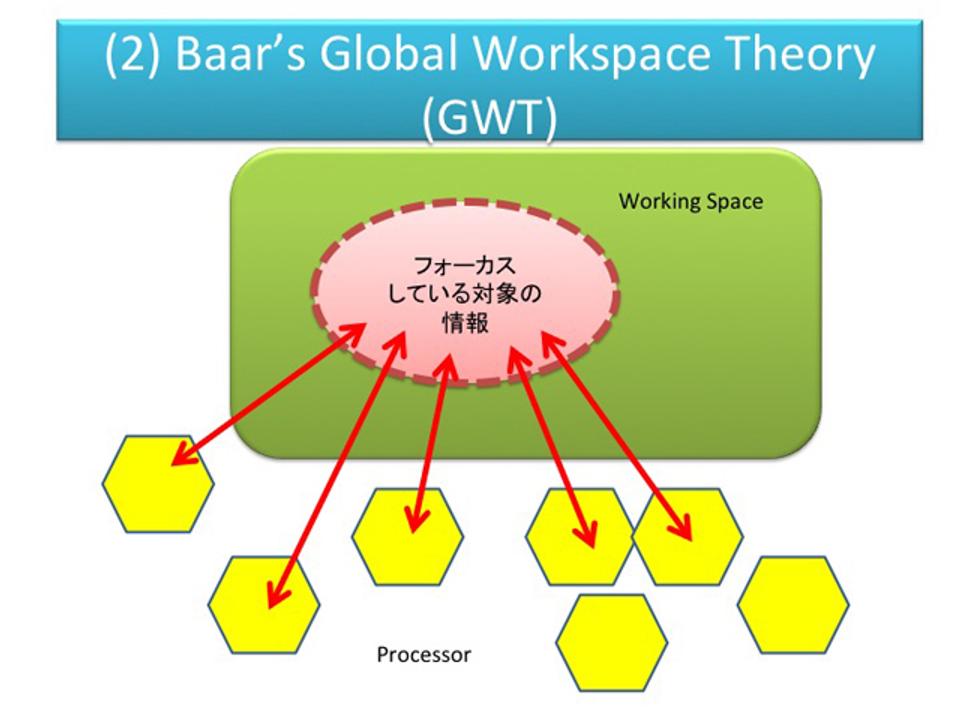
次に、Global Workspace Theoryです。情報が書き込まれるWorking Spaceといろいろなプロセッサ(小さな機能的知能)があって、プロセッサはWorking Spaceを処理する役割を持ちます。その中で、いま意識が向いている対象の情報をフォーカスして、いろいろな処理を書きます。フォーカスがずれると、プロセッサは新しくフォーカスされた情報にいって処理する。このモデルを「劇場モデル」といいます。認識する対象たちが舞台にあがっていて、舞台照明のフォーカスが当たっているところが意識なのだ、という考え方です。これは、黒板モデルと近い考え方ですが、より認知的な、意識的な描像になっています。みんな違う分野から似たようなことを言っているわけですね。
(3)Dennett's Multiple Draft Model
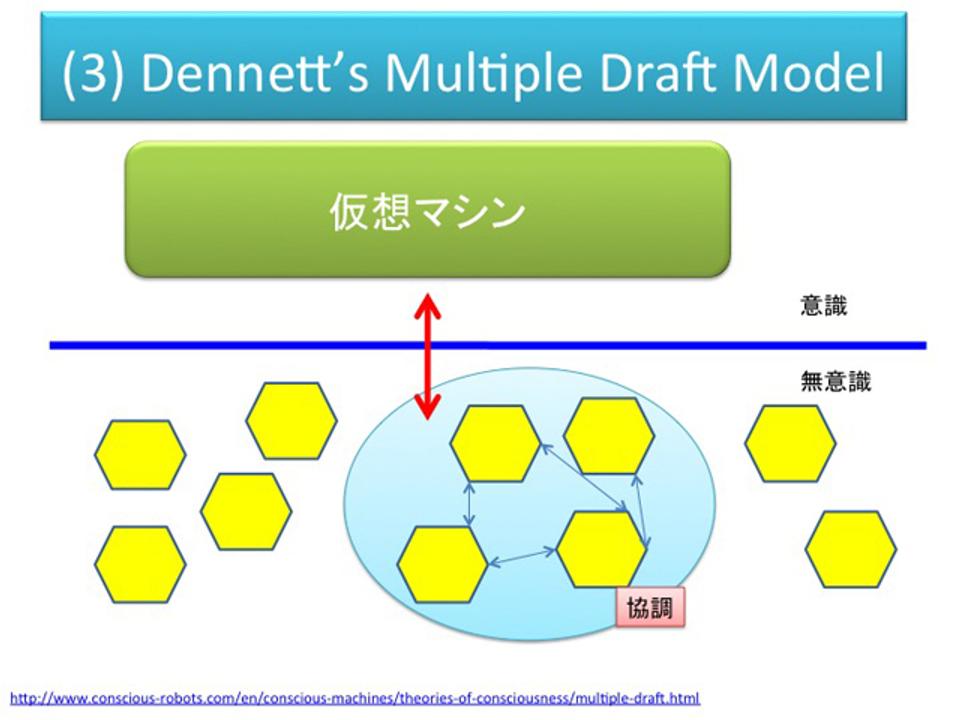
Multiple Draft Modelはプロセッサがある程度クラスタ化しています。ある問題があり、それに対してプロセッサが連携して解釈がされて書き換えられる。そういったモデルです。プロセッサが新聞記者みたいに、それぞれの専門の処理をこなしながら、記事(=認識)を形成していく、そんなイメージで、新聞社の編集モデルと言われます。
この3つのアイデアを掛けあわせたのが、次に紹介する人工知能です。
総合的な意識モデル
記憶領域(ワーキングメモリ)があり、そこにセンサーから新しい記憶が書き込まれます。Multiple Draft Modelのプロセッサたちが、そのスポットライト(注意)があたっているところの記憶をどんどん書き換えていく。
その裏には舞台裏の人々(過去の記憶や思考)があって、この人たちがこのスポットライトの当たっているところを情景に合わせてどんどん変えていく。簡単に言うと舞台セットを増やして行く。これは知能では何かと言うと、スポットライトの情報に合わせて過去の記憶や処理が呼び出されることを意味しています。
新しい場所にスポットライトが当たると、プロセッサにブロードキャストされて、再びプロセッサ側が「そうだよね、これはこういうことだよね」と注釈をしていく。こういうモデルです。
たとえば、リンゴを見ると、まず、そのリンゴが記憶領域に書き込まれる。すると、それにプロセッサたちが解釈を施す。同時に、過去のリンゴの記憶などが呼び出されて、そのリンゴのイメージが修飾されて行く、という過程です。
こうしたモデルで実際にゲームキャラクターの人工知能が作られました。それが「CERA-CRANIUM認識モデル」(Arrabales, R. Ledezma, A. and Sanchis, A. 2009)です。ゲームAI界隈では有名になったモデルなのですが、その基本はエージェントアーキテクチャモデルで、センサーから情報が入って、デバイス、意思決定と通ってアクチュエーター(エフェクター)に出ます。ポイントは、意思決定の部分が階層化されているところです。先ほどサブサンプションアーキテクチャの項で言ったように、知性はレイヤー化されるほどに賢くなります。
ひとつひとつは、先ほどのMultiple Draft Modelであり、記憶体(Workspace)があって、ここに意識がくるとプロセッサが書き込んでいくという形です。ただ、前述のように、構造が多層化されていて、多層化されたレイヤーの各レイヤーで記憶体(Workspace)とナレッジソースで書き込んでいくことで多層的に世界を解釈していきます。
ひとつ目はフィジカルレイヤー、モノが飛んできてよけるとか物理的な対応しかしません。さらに上位のミッションレイヤーは抽象的な判断と戦術を計算し、最後にコアレイヤーが意思決定を行います。このように三層構造のモデルになっています。これは、「Unreal Tournament」という銃で戦うゲームのキャラクターのAIに実装されて試されました。
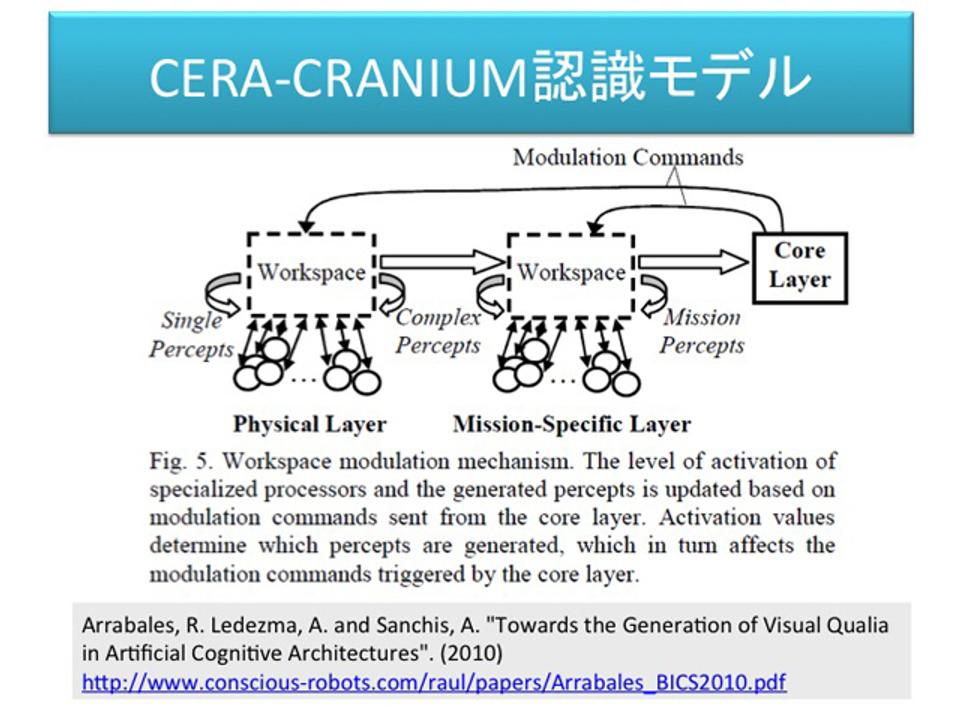
CERA-CRANIUM: A Test Bed for Machine Consciousness Research Arrabales, R. Ledezma, A. and Sanchis, A.International Workshop on Machine Consciousness 2009. Hong Kong. June 2009.
2K BotPrizeという、ちょっと変わったコンテストがあります。いろいろな人間と人工知能がゲーム上で戦って、「お前人間だろう」と、人間に一番間違えられた人工知能が優勝するというコンテストです。強い人工知能ではなくて、ゲームの中で人間らしい人工知能を作った人が勝ち。つまりデジタルゲームにおけるチューリングテストになっているのです。CERA-CRANIUM認識モデルを実装したこの人工知能は、2010年の2K BotPrizeで優勝しました。
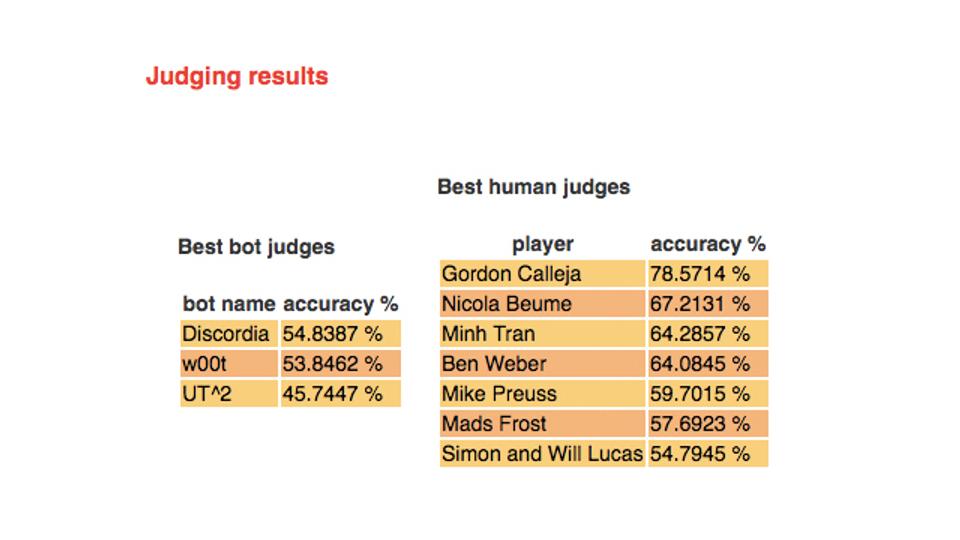
実際の成績表はこのように、人間と間違われた確率が記載されています。その値が最も高い人工知能が優勝となります。逆に、人工知能と間違えられる人間ってどうなのだろうという話もあります。ただ、うまいプレイヤーは限りなく人工知能に近くなっていくので、「あまりにも発達したプレイヤーは人工知能と区別がつかない」のではないか、とアーサー・C・クラークの警句になぞられて言うことができます。だから、人間らしい、ということは、ちょっと下手なほうがいいのですよね。どう下手かというのが問題なのですが。
さて、ここで、全体のテーマに戻ります。
これまで話をしてきたのが機械的な人工知能で、外側から知性を作ろうというアプローチでした。では、いつ人工知能は主観的な世界を持ち始めるのでしょうか? 意識モデルはまだ機械的な人工知能を作っているわけで、人工知能が主観的な世界を持っているかどうかはまだ微妙なところです。
いつ人工知能は主観的な世界を持ち始めるか? それに対する僕の答えですが、主観的世界を持つためには、身体を持たねばならないと考えています。身体を持たない人工知能は限りなく論理的です。ところが、身体というものを持ち世界に住みつくことによって、知能は大きな制限を受けると同時に大きな可能性を持つ。ここからは、身体性に着目して人工知能を考えていきたいと思います。
目的と価値消失
#カルチャーはお金システムの奴隷か?
日本人が知らないカルチャー経済革命を起こすプロフェッショナルたち




